Mediaan
De mediaan is een belangrijke maatstaf voor centrale tendens die minder gevoelig is voor uitbijters dan het gemiddelde. Lees hier hoe het wordt gebruikt en hoe te berekenen!
Wat is de Mediaan?
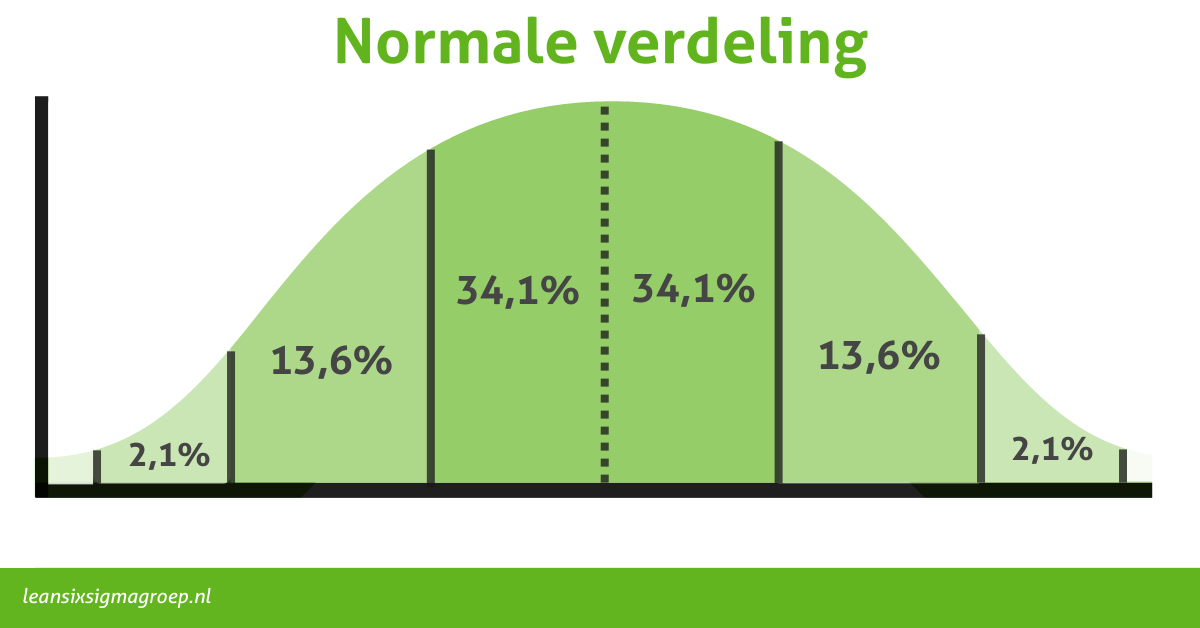
De mediaan is een maat van locatie die we gebruiken in de beschrijvende statistiek. Het is het middelpunt in een set gesorteerde getallen. Hiermee bedoelen we: de mediaan verdeelt de dataset in twee gelijke delen: 50 procent van alle datapunten bevinden zich aan de ene kant van de mediaan en 50 procent aan de andere kant.
Naast de mediaan, zijn er nog een aantal andere maten van locatie in een dataset aan te wijzen.
- Het gemiddelde, je kent ‘m vast wel: de som van alle datapunten in een dataset gedeeld door het aantal datapunten.
- De modus, iets minder bekend: de meest voorkomende waarde in een set getallen.
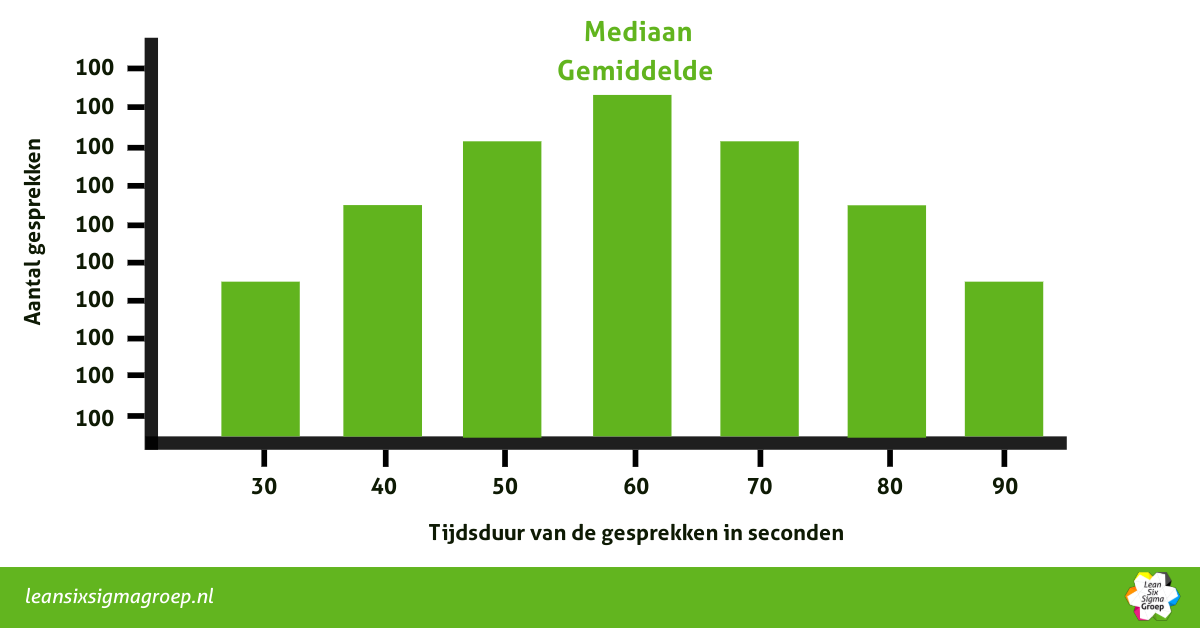
Stel, een callcenter heeft van duizend klantgesprekken de lengte van elk telefoontje bijgehouden. Als ze elk datapunt een plekje geven op een horizontale as (links staan hele korte telefoontjes en de langste telefoontjes staan helemaal rechts), dan kunnen we letterlijk de locaties gaan aanwijzen: hier bevindt het gemiddelde, hier de modus en hier de mediaan.