Hypothese
Met hypotheses van eureka-moment naar het ei van Columbus“Stel nou, dat het niet waar is, wat je denkt. Dat je het mis hebt. Dat kan. Want als je je eigen stem hoort op een cassettebandje, dan klinkt dat altijd afschuwelijk. Terwijl dat toch gewoon de stem is, zoals andere mensen hem horen. En stel nou, dat dat niet alleen maar met je stem is, maar met alles.”
In zijn vierde cabaretprogramma, Functioneel naakt, poneert Theo Maassen een voorlopige stelling die nog niet bewezen is, een hypothese. Een hypothese is vaak onderdeel van een onderzoek, waarbij ze het verwachte antwoord is op de onderzoeksvraag. Ze wordt getoetst met onderzoeken en/of experimenten.
Hypothesetesten voor belangrijke oorzaken
In de analysefase van Lean Six Sigma-projecten gebruiken we hypothesetesten om statistisch aan te tonen welke X’en kritisch zijn. Iets minder cryptisch: met hypothesetesten zoeken en (hopelijk) vinden we grondoorzaken voor het presteren van het proces dat we willen verbeteren, hypotheses testen is een middel om cruciale invloedsfactoren op te sporen.
Voordat ik verder ga: natuurlijk zijn er ook andere manieren om deze te vinden. Brainstormen of het interpreteren van de tekening van het huidige proces kan evenzogoed leiden tot een eureka-moment voor Green en Black Belts. Tegen het einde van de onderzoeksfase – in dit geval een verzamelnaam voor Define, Measure en Analyse – worden (eindelijk) de belangrijkste oorzaken voor het probleem dat we willen oplossen gevonden. Nu kunnen we gericht aan de slag met Improve en Control. Anders gezegd: na het eureka-moment kunnen we door naar de zoektocht naar het ei van Columbus.
Maar als het ook anders kan, waarom zouden we dan moeilijk doen met hypotheses en statistiek en zo? Ik hoor het je zeggen. Immers, niet alle veranderaars zijn even dol op statistiek als de ‘Professor of Industrial Statistics’ die mij tot Black Belt kneedde. Het simpele antwoord op deze vraag is: het hoeft niet, maar het mag wel. Hypothesetesten bieden eenvoudigweg een extra mogelijkheid grondoorzaken te vinden, er zijn meerdere wegen die naar Rome leiden. Tegelijkertijd verschaft het testen van hypotheses en het toepassen van statistiek informatie die we niet uit brainstormen of het interpreteren van de procestekening halen. We krijgen namelijk p-waardes en soms ook determinatiecoëfficiënten cadeau (niet stoppen met lezen nu, ik beloof je: dit wordt geen statistiek-les) en daarmee stellen we niet alleen vast – met alle mitsen en maren over (on)zekerheden die statistiek nu eenmaal altijd met zich meebrengt – of een oorzaak van invloed is op de procesprestatie, maar ook hoe groot die invloed is.
Een terzijde: er zijn – in mijn ogen slimme – Belts die eerst vooronderzoek doen naar grondoorzaken met brainstormen en het interpreteren van de procestekening, om pas dan met hypothesetesten aan de slag te gaan.
Schuld of onschuld met een hypothesetoets
Een hypothesetest bestaat altijd uit twee stellingen, de nulhypothese (H0) en de alternatieve hypothese (Ha). Bij de H0 gaan we ervanuit dat een oorzaak geen invloed heeft op de procesprestatie. Er is niets aan de hand, de variatie in het proces wordt door ruis veroorzaakt. De alternatieve hypothese, de woorden zeggen het eigenlijk al, stelt juist dat een oorzaak wel degelijk invloed heeft op de procesprestatie. Als Green of Black Belt hoop je in dit geval dus – wellicht stiekem – de alternatieve hypothese aan te kunnen nemen. Omdat je dan mogelijk een oorzaak gevonden hebt voor de probleemstelling die je onderzoekt.
Hypotheses komen we overal tegen, bijvoorbeeld ook in het rechtssysteem. In Nederland ben je onschuldig, tot het tegendeel bewezen is. Door bewijs te verzamelen tracht de officier van justitie het aannemelijk te maken dat de verdachte schuldig is aan een misdrijf. Wat hij probeert te realiseren, is dat we de nulhypothese (de verdachte is onschuldig; de beschuldigde heeft geen invloed gehad op de procesprestatie, in dit geval een misdrijf) verwerpen en de alternatieve hypothese aannemen.
Stappenplan voor hypothesetesten
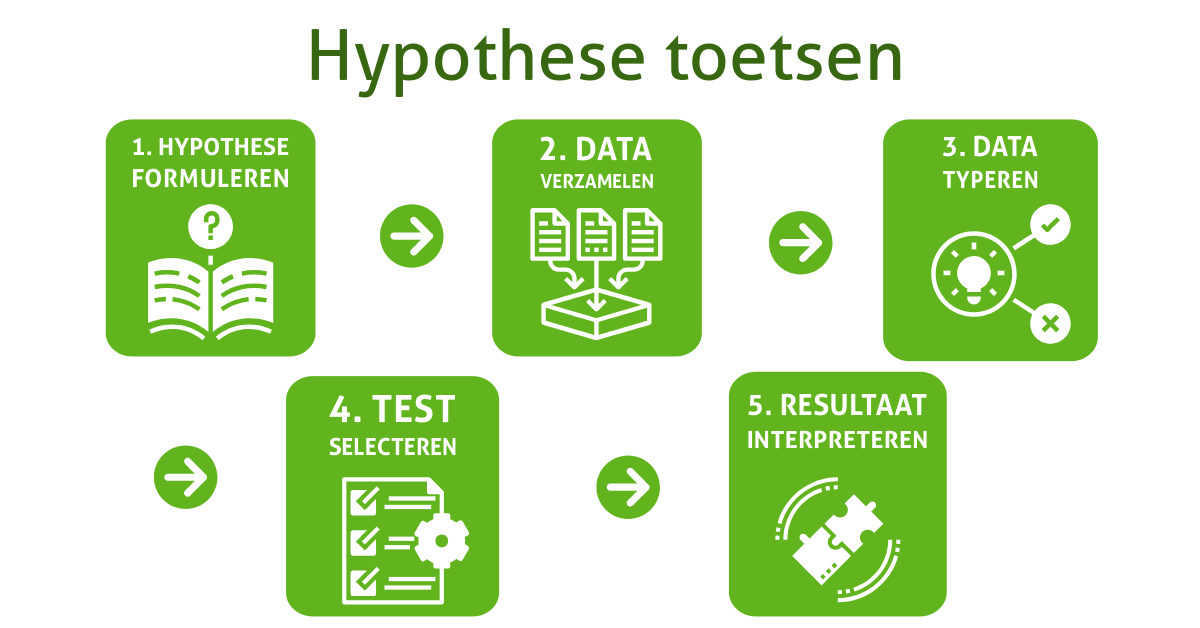
Het toetsen van hypotheses doen we in vijf stappen:
- Formuleer de hypothese
- Verzamel data en stel vast hoe de dataset verdeeld is
- Onderzoek met welk type data je te maken hebt en hoeveel groepen er zijn
- Selecteer de juiste statistische test
- Interpreteer de uitkomst van de test
- Formuleer de hypothese
Het probleem is dat de afhandeling van klachten te lang duurt. Er zijn twee soorten klachten. De nulhypothese kan dan zijn: het type klacht is niet van invloed op de doorlooptijd. De alternatieve hypothese is: de ene soort klacht wordt gemiddeld significant sneller afgehandeld dan de andere.
- Verzamel data waarmee je kunt zien of je hypothese klopt of niet
Verzamel data over je procesprestatie, maar met daarbij informatie over je hypothese. Bijvoorbeeld als je kijkt naar doorlooptijd en je wilt weten of er op maandag langere doorlooptijden zijn, dan wil je bij de data over doorlooptijd weten op welke dag deze is verzameld.
- Onderzoek met welk type data je te maken hebt en hoeveel groepen er zijn
Bij doorlooptijd spreken we van continue data (het woordenboek op onze website zegt hierover: ‘een set gegevens die allerlei tussenliggende waardes kan aannemen, bijvoorbeeld tijd, temperatuur, afstand. Vaak kan je hier een punt tussen zetten: rapportcijfers zijn continue waardes, je haalt een 6,8 of een 9,2’). Twee soorten klachten zijn discreet (‘bestaan uit een eindig aantal hele getallen waar tussenliggende waarden niet mogelijk zijn. Dit kunnen tellingen zijn of goed-fout data of verschillende schalen’). Er zijn twee groepen (want twee soorten klachten). Dit heeft invloed op welke test je kiest.
- Selecteer de juiste statistische test
Afhankelijk van of data continu of discreet is (koppeling naar een artikel over continue en discrete data) en op welke manier je informatie hebt over je hypothese wordt er een andere test gebruikt. In onze Green- en Black Belt-opleiding gaan we in op de keuzeboom, die je helpt de juiste statistische analyse te vinden. We gebruiken in dit geval een 2 Sample T-Test. Maar dat mag je verder vergeten. We doen in dat geval dertig metingen, de dataset is normaal verdeeld (meer over de normale verdeling kun je lezen op https://leansixsigmagroep.nl/lean-agile-en-six-sigma/de-normale-verdeling).
- Interpreteer de uitkomst van de test
We interpreteren de resultaten door te kijken naar de p-waarde, dit is de kans dat de 0-hypothese waar is. De p-waarde wordt uitgedrukt in een getal tussen 1 en 0. 1 is 100% en 0 is 0%. Als de kans dat de 0 hypothese waar is kleiner wordt dan 5% dan verwerpen we de 0-hypothese en accepteren we de alternatieve hypothese. Dus als de p-waarde groter dan of gelijk is aan 0,05, is er geen statistisch verschil en blijft de nulhypothese staan. Bij een p-waarde die kleiner is dan 0,05, wordt de nulhypothese verworpen, omdat er een statistisch verschil is aangetoond. Het – onder Belts even fameuze als beruchte – ezelsbruggetje hiervoor is: If P is Low, H0 must go. Ik hoop dat het je inmiddels niet zal verbazen dat veranderaars soms een gat in de lucht springen bij het aantreffen van een p-waarde onder de 0,05.
Concluderend, samenvattend zo je wilt, kunnen we stellen dat:
- Hypothesetesten gebruikt kunnen worden om grondoorzaken te vinden, en ze uitsluitsel geven over of een oorzaak echt te vinden is, of dat het toeval is en we verder moeten zoeken naar andere oorzaken.
- Het toetsen van hypotheses volgens een vast stappenplan gaat
- De uitkomst van een hypothesetest kan vertellen of een oorzaak van invloed is op de procesprestatie

In onze Green– en Black Belt-opleiding besteden wij ruim aandacht aan hypotheses en het testen ervan. We vertellen niet alleen wat het is, maar leren je het ook te doen. Mocht je daarin interesse hebben, neem dan eens contact met ons op via info@leansixsigmagroep.nl of 088 53 26 700.