Video laden...
Strategie
echt werkend krijgen
Lean Six Sigma Groep (LSSG) geeft trainingen op het gebied van Lean Six Sigma. We zijn onderdeel van Lean Agile Groep: een organisatie die met Lean en Agile technieken organisaties helpt om doelen te realiseren.
Binnen LSSG geven we verschillende trainingen van White, Yellow, Orange, Green tot Black en Master Black Belt trainingen. Onze trainingen zijn praktisch en worden gegeven door zeer ervaren trainers die ook nog eens humor hebben.
Dus wil je een leuke, inspirerende en praktisch toepasbare Lean training volgen? Dan ben je bij ons aan het goede adres. Verbetering vol energie!
Gedreven door verbetering
Onze ervaren trainers en consultants staan klaar om jouw organisatie verder te helpen. Zij combineren jarenlange praktijkervaring met diepgaande kennis van Lean, Agile en Six Sigma.
Dankzij hun betrokken aanpak maken ze de theorie direct toepasbaar in jouw werkomgeving zodat leren leidt tot blijvende verbetering.
Boost je kennis met onze
insights
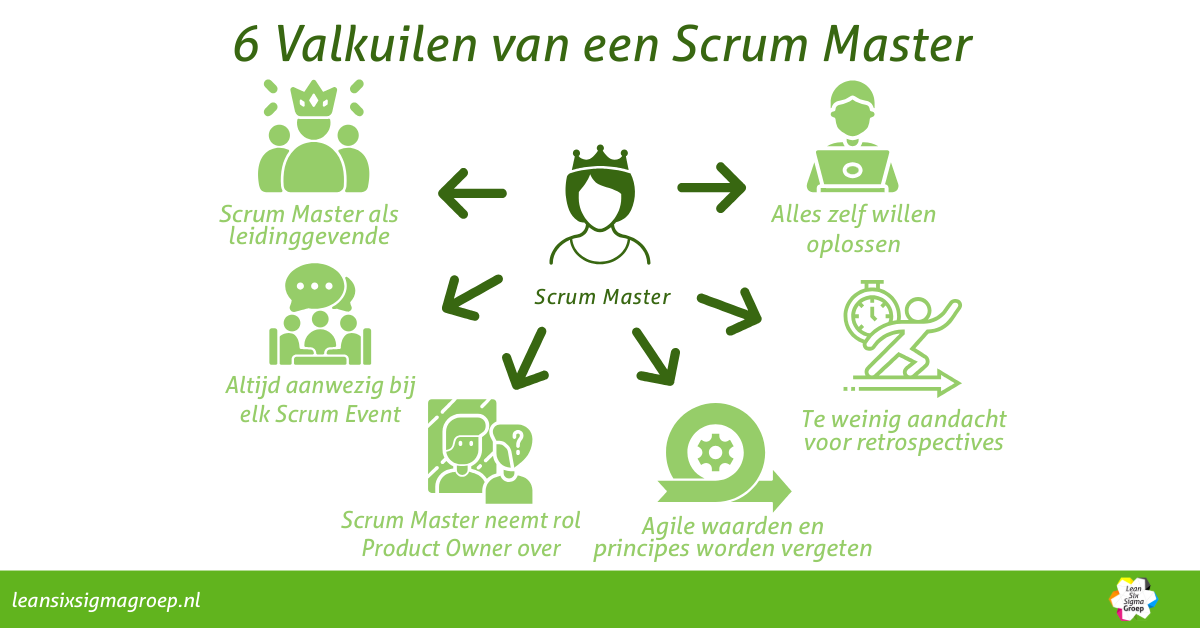
Veelvoorkomende Scrum-valkuilen en hoe de Scrum Master ze voorkomt
Als Scrum Master wil je teams effectief begeleiden, maar er liggen valkuilen op de loer. In dit artikel lees je 6 valkuilen voor Scrum Masters en hoe je ze voorkomt!
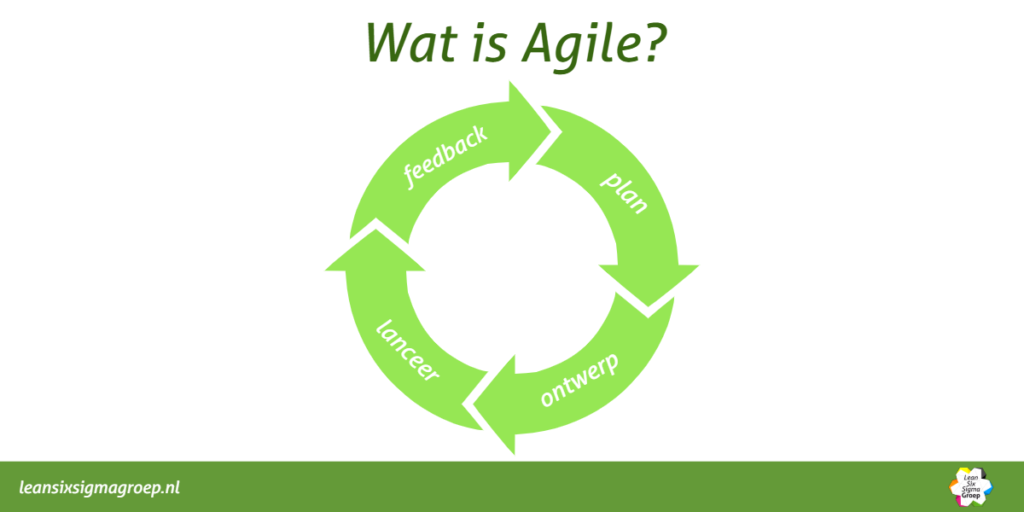
Agile Foundation: Jouw Startpunt in de Wereld van Agile & Scrum
Leer wat Agile écht inhoudt en hoe je de principes toepast in Scrum. De Agile Foundation training is de perfecte interactieve start voor iedereen die met Agile aan de slag wil.

Klantenanalyse met Lean Six Sigma
Klantgericht werken lijkt simpel, maar in de praktijk blijkt het vaak complexer dan gedacht. Laat zien hoe je met Lean Six Sigma-tools als het Kano-model en de Customer Journey écht inzicht krijgt in wat je klant belangrijk vindt.
Onze klanten & Partners
Vertrouwd door toonaangevende organisaties